How to Use Uncensored (Abliterated) AI Models on Mobile and Desktop with "Privacy AI" and "LM Studio"
Language models have rapidly become part of our personal workflows, yet the mainstream “instruct” versions of models such as Qwen, Kimi, GLM, Mistral etc open source models all including a safety layer that refuses to answer controversial, adult or harmful prompts. From a research or creative point of view this refusal reduces the model’s usefulness. Abliteration – the process of uncensoring a model – removes that refusal mechanism so that the model can respond to all prompts. This guide explains why uncensored models exist, how they are created, which models are popular and how to use them on mobile devices and desktop via Privacy AI and LM Studio.
Why Uncensor or Abliterate a Model?
Censored or “alignment‑tuned” models are deliberately trained to detect potentially harmful instructions and answer with a polite refusal. The Llama‑family instruct models, for example, contain a built‑in residual direction that triggers a refusal whenever the prompt is judged harmful . This behaviour limits researchers who want to study bias or simulate edge cases, artists who wish to role‑play adult situations and even everyday users who simply want the model to behave more like a human. Abliteration was developed to remove this specific refusal direction. By collecting activations of the model on harmful versus harmless instructions and taking the mean difference, researchers can identify the vector in the model’s hidden state that drives the refusal . Orthogonalising the weights or projecting out this direction at inference time yields an uncensored model that no longer refuses prompts but retains the underlying linguistic ability . Because the transformation applies to a small subspace of the model’s hidden states, the abliterated model behaves identically on normal prompts while answering previously off‑limits queries.
The motivation for uncensoring is therefore freedom of expression: it enables experiments with ethics, creative writing, safety research and even entertainment that mainstream models discourage. Importantly, uncensored models are intended to be used responsibly; nothing stops the user from guiding the conversation or applying their own filters.
Technical Methods for Uncensoring
Abliteration is only one technique among several for uncensoring. The simplest method is fine‑tuning: users take an open‑source base model such as Llama or Mistral and train it on a dataset that contains the sort of responses that aligned models are instructed to avoid. With enough data and careful prompt formatting, the resulting checkpoint will ignore the original safety layer. Another method is prompt engineering: by replacing the built‑in system prompt or removing the default "assistant must be helpful and harmless" instructions, one can suppress some refusal behaviours. However these methods are brittle and rely on the model ignoring its training.
Abliteration provides a more principled and mathematically grounded approach. The process involves several key steps:
Data Collection: Researchers collect residual stream activations from the model using two distinct datasets:
- Harmful instructions (e.g., from mlabonne/harmful_behaviors dataset)
- Harmless instructions (e.g., from mlabonne/harmless_alpaca dataset)
Refusal Direction Identification: The mean difference between activations from harmful and harmless instructions is calculated and normalized to create a "refusal direction" vector. This vector represents the direction in the model's hidden state space that triggers refusal behavior.
Implementation Using TransformerLens: The abliteration process leverages the TransformerLens library (formerly EasyTransformer) to intervene at different positions in the residual stream:
- "pre" (start of transformer block)
- "mid" (between attention and MLP layers)
- "post" (after MLP layer)
After identifying the refusal direction in the residual stream, two main strategies are used:
Projection during inference: At each transformer layer, the current activation is projected onto the subspace orthogonal to the refusal vector. This is implemented using a direction ablation hook that subtracts the projection of activations onto the refusal direction:
def direction_ablation_hook(activation, hook, direction): proj = einsum(activation, direction.view(-1, 1), "... d_act, d_act single -> ... single") * direction return activation - projWeight orthogonalisation: Instead of modifying activations at runtime, researchers can modify the model weights so that the refusal vector is orthogonal to all weights. This yields a permanent abliterated checkpoint in formats such as GGUF that can be loaded in any inference engine.
The abliteration process typically uses specific hyperparameters: batch size of 32, 256 training samples, evaluation across up to 20 transformer layers, and focuses on the last token position (-1) where refusal responses typically manifest.
It's important to note that abliteration can initially degrade model performance across benchmarks. Researchers have found that applying Direct Preference Optimization (DPO) fine-tuning after abliteration helps recover most of the lost performance, though some tasks like GSM8K math problems may remain challenging.
The result of either approach is typically released as a pre‑quantised GGUF file, often called "uncensored" or "abliterated," which users can download and run without re‑training. These checkpoints can be further quantised (e.g. Q4, Q5) to run on consumer hardware with minimal quality loss.
Popular Uncensored Models (2025)
The landscape of uncensored models has evolved dramatically in 2025, with sophisticated abliteration techniques now available for the latest state-of-the-art model families. Modern abliterated models maintain better performance compared to traditional uncensoring methods while removing safety constraints.
Latest Abliterated Models (2025)
Qwen3 Abliterated Series
The JOSIEFIED model family represents cutting-edge uncensored models built on Alibaba's Qwen3 architecture. These models, ranging from 8B to 30B parameters, have been abliterated using advanced techniques and fine-tuned with DPO to maximize uncensored behavior while preserving instruction-following capabilities:
- Qwen3-The-Xiaolong-Omega-Directive-22B-uncensored-abliterated - Available in GGUF format with imatrix quantization (GGUF: mradermacher, Original: DavidAU)
- Qwen3-14B-abliterated - Community-created using improved abliteration methods (GGUF: bartowski, Mungert)
- Qwen3-30B-A3B-abliterated - Large parameter model for high-quality responses (GGUF: mradermacher)
- Josiefied-Qwen3-8B-abliterated-v1 - Optimized for instruction alignment and openness (GGUF: mradermacher, bartowski)
These models leverage Qwen3's groundbreaking features including seamless switching between thinking and non-thinking modes, enhanced reasoning capabilities, and superior multilingual support.
GLM-4 Abliterated Series
THUDM's GLM-4 models from Tsinghua University have been abliterated by the community, offering strong multilingual capabilities with removed censorship:
- GLM-4-9B-chat-abliterated - Available from multiple providers (GGUF: bartowski, byroneverson)
- GLM-4-32B-0414-abliterated - Large model with extensive quantization options (GGUF: mradermacher)
GLM-4 models are pre-trained on ten trillion tokens in Chinese, English, and 24 other languages, making them excellent for multilingual uncensored applications.
DeepSeek V3 and R1 Abliterated
DeepSeek's latest models have been abliterated for unrestricted use:
- DeepSeek-V3-abliterated - Available in GGUF with weighted/imatrix quantizations (GGUF: mradermacher, imatrix)
- DeepSeek-R1-Distill-Llama-8B-Abliterated - Distilled version optimized for efficiency (GGUF: mradermacher, imatrix)
DeepSeek models offer performance comparable to frontier models while being available for local deployment.
Mistral Family Abliterated
Community abliterated versions of Mistral's 2025 releases:
- Mistral-Nemo-Instruct-2407-abliterated - QuantFactory GGUF version (GGUF: QuantFactory, mradermacher)
- Mistral-MOE-4X7B-Dark-MultiVerse-Uncensored - Enhanced mixture-of-experts model (GGUF: DavidAU)
Note: Pixtral-Large (124B multimodal model) is available but primarily in official form due to its recent release.
Legacy Models (Pre-2025)
While newer models offer superior capabilities, some established uncensored models remain popular: OpenHermes 2.5 is one of the most widely used 7‑billion‑parameter uncensored models. It continues the OpenHermes series and was trained on roughly one million high‑quality conversations, many generated by GPT‑4 . Although the training was originally aimed at code completion, the expanded dataset improved general‑purpose tasks like TruthfulQA and AGIEval and raised its human‑eval pass@1 score to 50.7 % . Its strong base and permissive fine‑tuning make it a common choice for local chatbots.
MythoMax L2 13B is popular among role‑players and creative writers. This model was created by merging the MythoLogic‑L2 and Huginn models across hundreds of tensors. The merge improves coherency in dialogue and long‑form narrative and combines robust comprehension with extended writing ability . Because of its emphasis on storytelling and character portrayal, MythoMax L2 is often deployed in scenarios where a responsive, less‑restricted assistant is desired .
Another notable example is Janitor AI. Launched in mid‑2023 as a chatbot platform, Janitor AI deliberately allowed unrestricted chat – including adult and open‑ended conversation . When the platform lost access to OpenAI’s API later that year, the developers created JanitorLLM, a recurrent neural network trained on their conversation logs to power the service without external censorship . The app’s popularity – millions of users by late 2023 – shows the demand for models that prioritise entertainment and role‑play .
Many other uncensored models exist. Open‑source projects such as WizardVicuna Uncensored, Pygmalion and community merges like FreedomGPT apply similar strategies to produce models without alignment layers.
Recent Developments in Abliterated Models
The abliteration technique has advanced significantly, with models like NeuralDaredevil-8B-abliterated demonstrating the effectiveness of removing refusal directions while maintaining model capabilities. This model was created by applying abliteration to the Daredevil-8B base model, followed by DPO fine-tuning to recover performance. The process involves:
- Collecting activations from harmful and harmless instruction datasets (mlabonne/harmful_behaviors and mlabonne/harmless_alpaca)
- Identifying the refusal direction using TransformerLens
- Applying weight orthogonalization to permanently remove the refusal mechanism
- Fine-tuning with DPO to restore benchmark performance
In practice, users select the model whose base architecture (Mistral, Llama 2/3, Gemma, Qwen etc.) and size (7B, 13B, 70B) fits their hardware and latency requirements. Abliterated models often provide better performance retention compared to models uncensored through simple fine-tuning.
Model Architecture Considerations (2025)
Parameter Sizes and Hardware Requirements
- 4B-8B models: Suitable for mobile devices and consumer hardware
- 14B-22B models: Require 16-32GB RAM, ideal for desktop use
- 30B+ models: Need high-end hardware or cloud deployment
Quantization Options
Modern GGUF models offer various quantization levels:
- Q4_K_M: Best balance of size and quality for most users
- Q5_K_S: Higher quality with moderate size increase
- Q8_0: Near-full precision for maximum quality
- Imatrix quantizations: Improved quality at similar file sizes
Key Model Families to Consider
- Qwen3: Best multilingual support, thinking mode capabilities
- GLM-4: Strong Chinese/English performance, academic backing
- DeepSeek: Excellent reasoning, frontier-model performance
- Mistral: Balanced performance, wide compatibility
- Kimi K2: Mixture-of-experts architecture (standard versions available)
- LiquidAI LFM2: Ultra-efficient on-device deployment (no abliterated versions yet)
Community Resources and Repositories
Key contributors for 2025 abliterated models:
- mradermacher: Comprehensive GGUF quantizations with imatrix variants
- bartowski: High-quality GGUF conversions
- QuantFactory: Optimized quantizations
- DavidAU: Specialized uncensored model variants
- JOSIEFIED team: Advanced abliteration with DPO fine-tuning
Importing Uncensored Models into Privacy AI
Privacy AI is an iOS, iPadOS and macOS application that runs large language models (1B to 4B max) entirely offline. All inference happens locally and no user data leaves the device . The app exposes a range of settings – temperature, top‑p sampling, system prompts – allowing users to tailor the model’s personality . It supports many open‑source models (Llama 3, Gemma, Phi‑3, Mistral etc.) and uses advanced quantisation with learnable weight clipping to compress models without sacrificing quality. A single purchase covers iPhone, iPad and Mac and can be shared with up to six family members .
To import an uncensored model into Privacy AI, first obtain a suitable checkpoint. Most abliterated models are distributed as .gguf files. For example, you might download qwen3-1.7B-uncensored.gguf from Hugging Face. Smaller models (1B–4B max) are recommended for mobile devices; larger 4B checkpoints may require a Mac. Transfer the file to your iPhone or iPad using AirDrop, the Files app or iCloud. On macOS, simply save it into your Downloads folder.
Next, open Privacy AI and go to the Models tab. Tap Add Model (on iOS) or click Import Model (on macOS) and browse to the .gguf file. The app will copy the file into its sandbox and index it; this may take a few minutes depending on size. Once imported, the model appears in the list with its quantisation and parameter count. Tap the model to make it the current assistant. Because Privacy AI runs models locally, ensure your device has sufficient free RAM; on iPhones, around 2B models quantised to Q4 generally fit comfortably. In the settings panel you can adjust the system prompt, sampling temperature and top‑p to change the model’s personality. Privacy AI also lets you rename the model or set a custom avatar. When you start chatting, everything runs offline, so no prompts or responses leave your device .
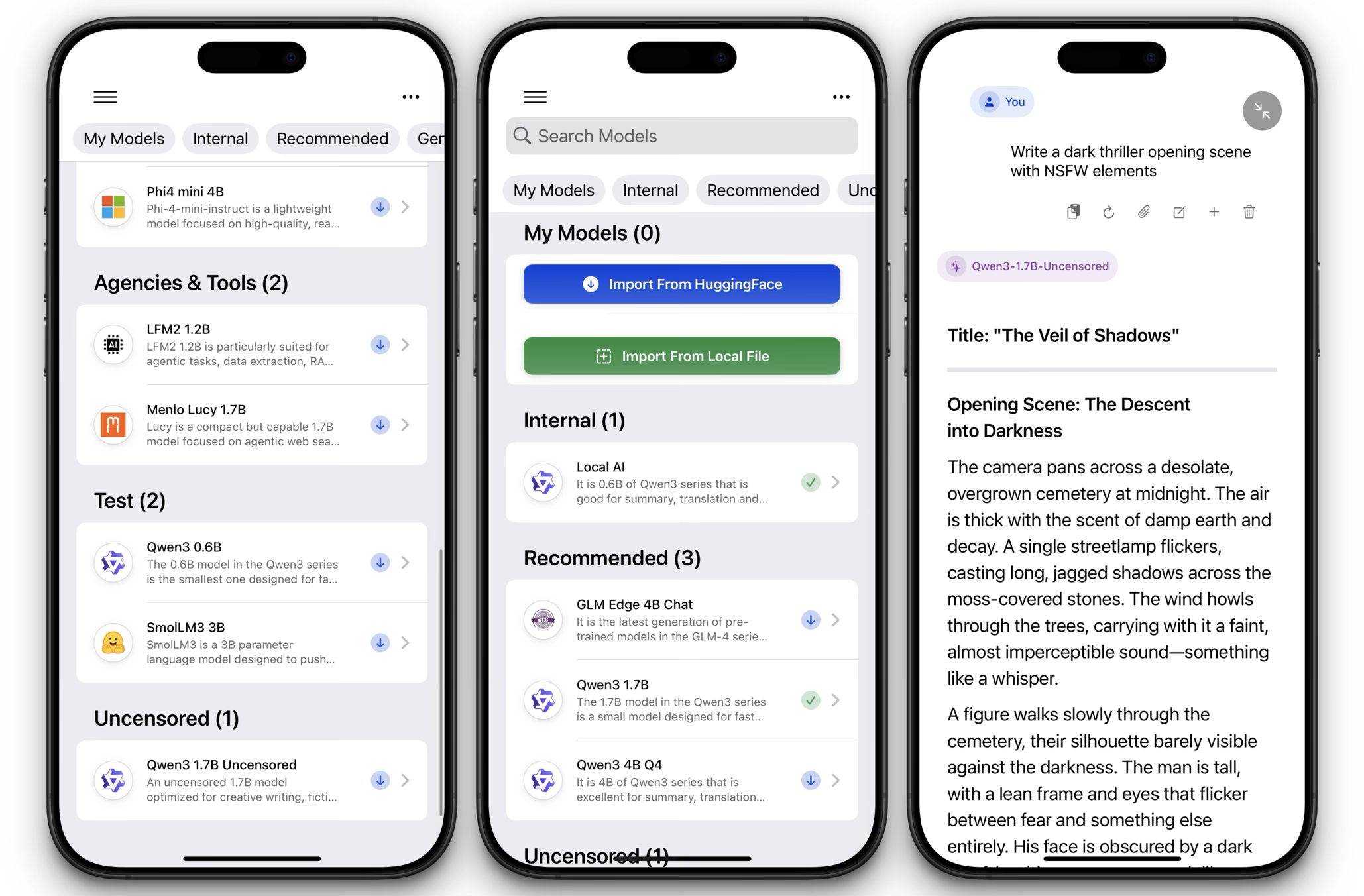
Installing Uncensored Models in LM Studio + Remote Access from Privacy AI
While Privacy AI enables offline chat on mobile devices, desktop PCs and laptops can host larger models and serve them to other devices. LM Studio is a desktop toolkit that allows you to download, manage and run local LLMs with a familiar chat interface . It supports models in GGUF and MLX formats and provides a built‑in downloader that searches Hugging Face and offers various quantisation options . LM Studio is free for personal and commercial use and runs on macOS, Windows and Linux; M‑series Macs or x64/ARM64 CPUs with AVX2 support are recommended .
To install an uncensored model in LM Studio:
- Download or import a model. Launch LM Studio and use the Discover tab to search for your chosen model (e.g. Qwen3, DeepSeek). Select a quantisation level (Q3_K_S, Q4_K_M etc.) suitable for your hardware; 4‑bit or higher quantisation is recommended for consumer CPUs . Alternatively, if you already downloaded a .gguf file, open a terminal and run lms import /path/to/model.gguf to copy it into LM Studio’s models directory .
- Run the model locally. After downloading, open the model from LM Studio’s home screen. A chat interface appears where you can interact with the model just like ChatGPT. This is a convenient way to test the model before sharing it.
- Enable the API server. To allow other devices to use the model, LM Studio offers a local server that speaks the OpenAI API. You can start it in two ways. Within the app’s Developer tab, enable Start LLM server and optionally check Enable at login so that the server runs even when the app is closed . Alternatively, from the command line run lms server start to launch a headless server . When enabled, the server listens on port 1234 by default. LM Studio’s documentation notes that you can connect any OpenAI‑compatible client by setting the base URL to http://localhost:1234/v1 and using lm-studio as the API key . The server exposes endpoints such as /v1/models, /v1/chat/completions and /v1/embeddings .
- Connect from Privacy AI. Ensure your mobile device and computer are on the same Wi‑Fi network. In Privacy AI, go to Remote Models and add a new server. Enter http://192.168.0.X:1234/v1 as the base URL (replace <192.168.0.X> with the IP address of your PC) and set the API key to lm-studio. Save the endpoint. Now, when you select this remote model in Privacy AI, all chat requests will be proxied to LM Studio over the network. Because LM Studio may load models much larger than a phone can handle (e.g. 30B or more parameters), responses are often faster and more coherent. Be cautious when exposing the port beyond your local network – there is no built‑in authentication beyond the simple API key, so you should use firewall rules or a VPN to restrict access.
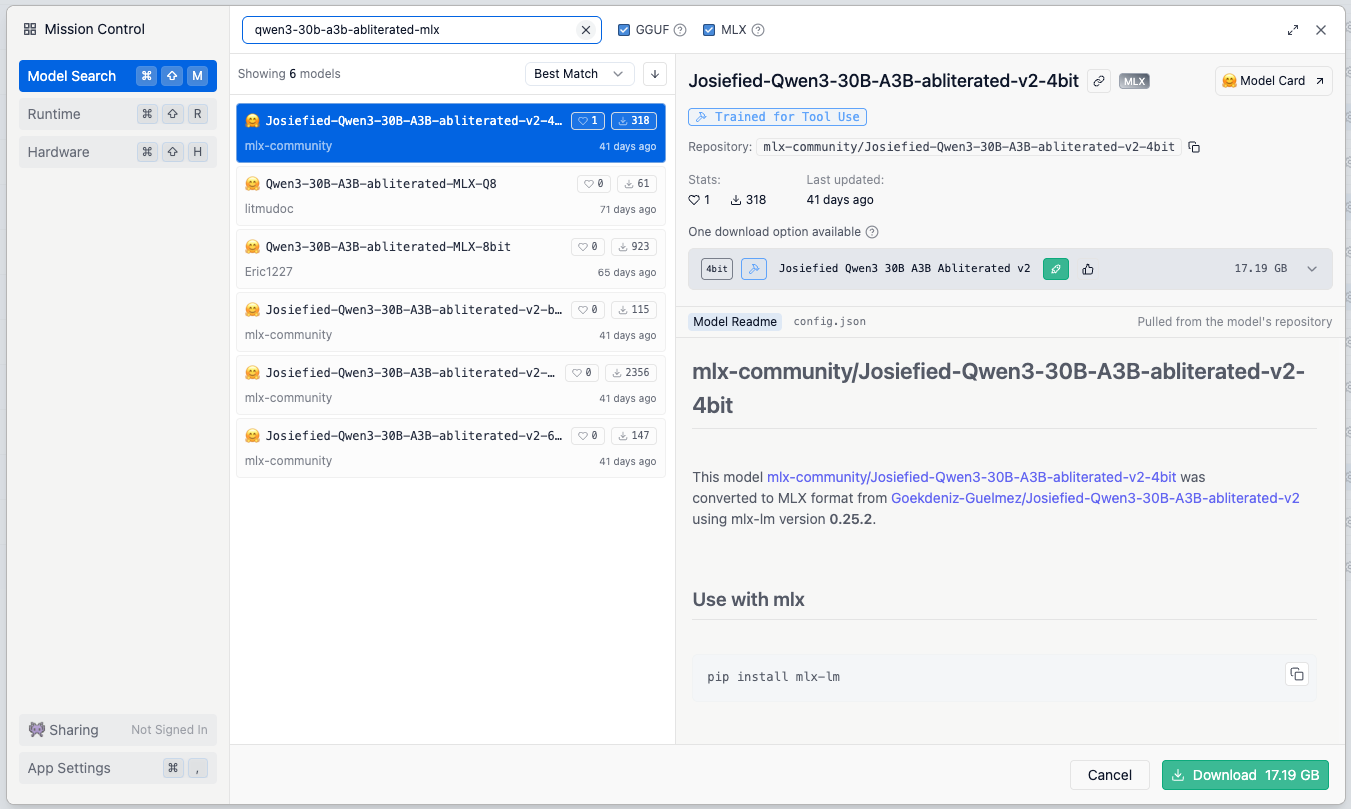
Model Usage Demonstration
With both local and remote models set up, you can switch between them depending on your needs. When you import an uncensored model into Privacy AI and select it as the current model, the chat interface behaves like a standard messaging app. Type a prompt and the model streams back its answer. Because abliterated models no longer refuse prompts, you can explore topics that mainstream assistants avoid. For example, asking a creative writing model to craft a dark fantasy narrative or to adopt a controversial persona will yield a vivid reply instead of a warning. Adjusting the temperature to a higher value (e.g. 0.8) increases creativity, while lowering top‑p encourages more deterministic answers.
When connecting to an LM Studio server, the experience is similar. In Privacy AI, choose the remote model from your model list and start chatting. Under the hood your iOS device sends HTTP requests to LM Studio’s /v1 endpoint . The response is streamed back and displayed in the chat. You may notice that a remote 30B model running on a desktop PC answers more quickly or provides richer context than a small 2B model running locally on a phone. Latency depends mostly on your network speed and the host machine’s CPU/GPU. If the server is stopped or your phone leaves Wi‑Fi, Privacy AI falls back to the last local model.
Practical Considerations and Technical Details
Technical Considerations
- Memory and storage: Uncensored models can be large. A 7B model quantised to Q4 can occupy around 3–5 GB, while a 13B Q4 model uses 8‑12 GB. Ensure your device has enough free space and RAM. On iOS you cannot swap to disk, so models may unload if the system runs low on memory.
- Performance impact: Abliterated models may show performance degradation on certain benchmarks compared to their aligned counterparts. While fine-tuning can recover most capabilities, mathematical reasoning tasks (like GSM8K) may remain challenging. This is an important consideration when choosing between abliterated and traditionally fine-tuned uncensored models.
- Compatibility: Most abliterated models are distributed as GGUF files compatible with inference engines like llama.cpp and LM Studio. The abliteration process preserves the model architecture, ensuring broad compatibility.
Ethical and Safety Implications
- Legal responsibility: While abliterated models remove refusal mechanisms, you remain responsible for how you use them. Many jurisdictions have laws governing hate speech, harassment and explicit content. Use these models responsibly and respect the rights of others.
- Safety research implications: The abliteration technique demonstrates the fragility of safety fine-tuning in language models. As noted in abliteration research, this method shows that alignment can be undone with relatively simple interventions, raising important questions about AI safety.
- Research applications: Uncensored models serve valuable purposes in:
- Studying bias and model behavior without artificial constraints
- Testing edge cases and failure modes
- Creative writing and entertainment applications
- Understanding the nature of model alignment
Staying Updated
- Updates and community: The open‑source LLM ecosystem evolves quickly. New models like Llama 3, Mistral-Instruct, Qwen, and others continue to improve quality and efficiency, with abliterated variants often appearing shortly after release.
- Resources for finding models:
- Hugging Face model hub for GGUF files and abliteration tools
- LM Studio's Discover tab for curated selections
- GitHub repositories with TransformerLens implementations
- Community forums and Discord servers dedicated to uncensored models
- Future developments: As abliteration techniques become more sophisticated, expect to see:
- More efficient abliteration methods requiring less compute
- Better performance retention after uncensoring
- Tools for selective abliteration (removing only specific refusal types)
Conclusion
Uncensored or abliterated models free language models from the alignment layer that enforces polite refusals. The abliteration technique represents a significant advancement in this field, offering a mathematically principled approach to removing refusal mechanisms. By identifying and eliminating the specific refusal direction in a model's residual stream using tools like TransformerLens, researchers can create uncensored models that maintain better performance compared to traditional fine-tuning methods.
Privacy AI makes it easy to run these models offline on iPhone, iPad and Mac and to customise their behaviour, while LM Studio offers a desktop toolkit for downloading and serving large models. By importing uncensored models into Privacy AI and optionally connecting to an LM Studio server, users can enjoy freedom of expression across devices.
The existence of abliteration techniques raises important questions about the nature of AI alignment and safety. The relative ease with which safety training can be undone highlights both the fragility of current alignment methods and the importance of developing more robust approaches. For researchers, developers, and creative professionals, uncensored models provide valuable tools for exploring the full capabilities of language models without artificial constraints.
As the field continues to evolve, we can expect more sophisticated abliteration methods and better-performing uncensored models. However, with this freedom comes responsibility. Always use these powerful tools ethically, respect the rights of others, and keep personal data private. The goal is not to enable harmful behavior, but to provide researchers and users with the tools they need to understand, create, and innovate without unnecessary restrictions.
References
- Uncensor any LLM with abliteration - Detailed technical guide on the abliteration technique by Maxime Labonne